Introduction
At Vinissimus, we have recently launched a virtual sommelier that suggests wines given a text of a food dish.
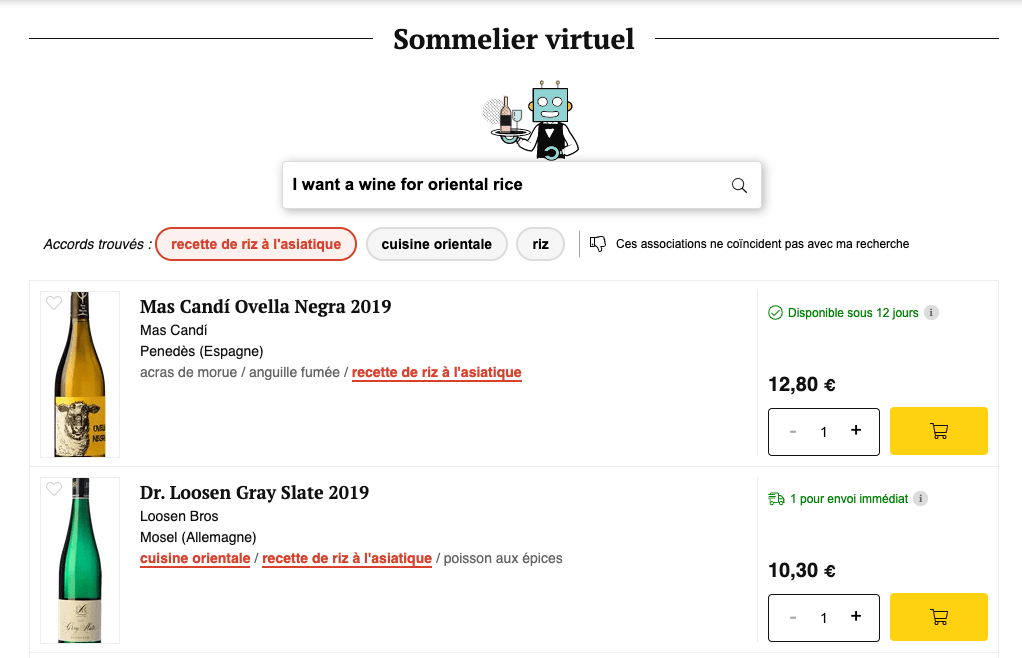
In this article we'll explore the development of this suggester, trained with machine learning and consumed directly from the browser.
Prerequisites
- Have a database with many wines (there are +15000 wines in our database), with food labels (in total we have +1000 food labels).
Requirements
- Given a text, for example "Wine for paella" (or just "paella"), returns all the labels among the +1000 we have that are related: paella, seafood, rice, shrimp...
- Fast to train and use.
Type of problem to solve
Before starting with the project, it's necessary to know what kind of problem we are facing; regression, binary-class classification, multi-class classification, multi-class multi-label classification... To know this, we must know what each term is.
Regression
The regression makes sense when the value we want to predict is a numerical value that can give a new value outside the training values.
It's not the type of problem we want to solve ❌...
Classification
We use a classification, when the value we want to predict is a value within a set of predefined values (classes).
Okay, this is what we want ✅.
Within the classification, there are:
- Binary single-label: predicts a class between two classes (not our case, since we have 1000 classes ❌ ).
- Multi-class single-label: predicts a class between more than two classes (not our case either, since we don't have to choose 1. For example for paella we can recommend: paella, rice and seafood labels ❌ ).
- Multi-class multi-label: predicts a range of classes between more than two classes (This is what we want ✅ ).
It is important to know that our problem is a multi-class multi-label classification as this will determine some hyperparameters to use such as the loss function.
Exploring techniques/tools
Now that we know that the problem we want to solve is a multi-class multi-label classification, let's explore a few ways in order to solve the problem, considering that we want to load the model directly from the browser.
Tensorflow.js
Spoiler: we'll discard it.
Tensorflow is one of the most used frameworks for deeplearning, it allows you to create neural network models in a simple and declarative way. It also has a JavaScript version that allows us to load an already trained model from the browser to make predictions. So initially this tool could be considerated adequate to solve the problem.
Tensorflow works with tensors (n-dimensional vectors) as a lingua franca, so to work with text we must transform the text into tensors. To do this there are several embedding models, however we'll use the Universal Sentence Encoder that is already optimized to work from the browser, because to make the prediction we must also pass the text to tensor from the browser.

We can transform our entire dataset into encodings with:
import '@tensorflow/tfjs-node-gpu'
import * as use from '@tensorflow-models/universal-sentence-encoder'
import data from './data.json'
import _ from 'lodash'
import fs from 'fs'
console.log('Encoding...')
use
.load()
.then((model) =>
model.embed(data.map(({ text }) => text.trim().toLowerCase()))
)
.then((r) => {
fs.writeFileSync(
'embeddings.json',
JSON.stringify(_.chunk(Array.from(r.dataSync()), 512))
)
console.log('Saved...')
})And use a network architecture like this:
import * as tf from '@tensorflow/tfjs'
import '@tensorflow/tfjs-node-gpu'
const model = tf.sequential()
model.add(
tf.layers.dense({
inputShape: [512],
activation: 'relu',
units: 512,
})
)
for (let i = 0; i < 10; i += 1) {
model.add(
tf.layers.dense({
inputShape: [512],
activation: 'relu',
units: 512,
})
)
}
model.add(
tf.layers.dense({
activation: 'sigmoid',
units: classes.length,
})
)
model.compile({
loss: 'binaryCrossentropy',
optimizer: 'adam',
metrics: ['accuracy'],
})To train the model, pass it the encodings that we have generated:
import embeddings from './embeddings.json'
import outputs from './outputs.json'
const dataset = tf.data
.generator(async function* gen() {
for (let i = 0; i < embeddings.length; i += 1) {
yield {
xs: embeddings[i],
ys: outputs[i],
}
}
})
.batch(128)
model.fitDataset(dataset, { epochs: 600 }).then((history) => {
console.log(history)
model.save('file://./model')
})Of course there are many hyperparameters to play with: number of epochs, batch size, dense layer activation functions, optimizer, etc. However, after spending a lot of time we haven't found yet the best way to solve two problems that had arisen when we tried to solve the problem with Tensorflow:
- The time needed to train with +1000 classes and +400000 examples in the dataset made it unfeasible. Around 10 days of training.
- Testing with fewer classes and examples works well... But calculating the embeddings with the Universal Sentense encoder is a bit expensive (although the prediction is cheaper). To make the prediction we have to pass the embeddings so it's a price to pay.
One of the requirements (Fast to train and use) was not feasible with Tensorflow.js. We have to look for other alternatives!
FastText
Spoiler: This is what we finally use.
FastText is a Facebook tool that, among other things, is used to train text classification models. Unlike Tensorflow.js, it is more intended to work with text so we don't need to pass a tensor and we can use the text directly. Training a model with it is much faster and there are fewer hyperparameters. Besides, to use the model from the browser is possible through WebAssembly. So it's a good alternative to try. Moreover, we can directly use the fastText CLI, which makes it easier to test combinations.
After some tests, we found that fastText met the requirements. The following sections of the article will focus on the use of FastText.
Preparing the data & data augmentation
FastText expects a text file with different labels and texts with a similar format to this one:
__label__1606 __label__433 rabbit with mushroomsThe text rabbit with mushrooms is related to the labels with the id 1606 (id of the "rabbit with mushrooms" label) and 433 (id of the "rabbit" label).
The initial problem is that we don't start from ready-made sentences because the search engine didn't exist before, so we have to generate them from each label we have.
Surely we could put more labels on it, for example, white meat, but how do we make all those relationships?
What we did is to save an array with each label in a JSON, and make several scripts for each label to have extra information such as: synonyms, plurals, closest words, relations, etc. For each language we have (en, es, it, fr and de).
- For synonyms, plurals and missing translations we used the API of DeepL.
- For closest words, FastText has available Wikipedia vectors to search the closest words with k-nearest.
- For relations, we simply made several iterations in the array applying logics like: all words that have "beef, goat, etc" are marked as children of "red meat". And so on with all the detected labels that were more generic, such as: fish, rice, pasta, etc.
Apart from normalizing each text with this simple JS function:
function normalize(text = '') {
return text
.trim()
.toLowerCase()
.normalize('NFD')
.replace(/[\u0300-\u036f]/g, '')
}Example of 2 items of this array:
[
{
"id": "1109",
"txt": {
"es": "revueltos",
"fr": "oeufs brouilles",
"de": "ruhreier",
"it": "uova strapazzate",
"en": "scrambled eggs"
},
"similar": ["fritos", "revuelto", "egg", "huevo", "estrellados"],
"parent": ["779"]
},
{
"id": "779",
"txt": {
"es": "huevos",
"fr": "oeuf",
"de": "eier",
"it": "uova",
"en": "eggs"
},
"similar": [
"uovo",
"œuf",
"ei",
"kartoffel omelette",
"omelette",
"huevo",
"spiegelei",
"tortilla de patatas",
"tortilla",
"gebraten",
"tortillas",
"fritos",
"frito",
"fichi",
"ous"
],
"parent": []
}
]Preparing this array has been the most laborious part of the whole process. Once this array is ready, then we can generate with the format that FastText is expecting as many food sentences as possible by adding plurals, synonyms, knowing which generic labels to put for each sentence, etc. Besides we can add extra words to the sentences such as "Wine for ...", "Pairing for ...", etc.
So we went from 1000 labels, and therefore 1000 possible sentences with 1 label per sentence, to increase to 74,000 sentences and each sentence with several labels.
Training
Once the file with all the sentences and labels has been generated, we can train the model. With FastText we can do this directly with the CLI. After playing a little with the hyperparameters, this was the command that best converged our loss function:
./fasttext supervised -input data/dataset.txt -output model -epoch 50 -lr 0.1 -lrUpdateRate 1000 -minCount 1 -minn 3 -maxn 6 -wordNgrams 2 -dim 100 -neg 20 -loss ovaAs a loss function we use the ova (one vs all) which is the one that best suits us for a multi-class multi-label classification problem. Other parameters such as epoch, learning rate, etc, are the result of playing with the hyperparameters so that the loss function is as close to 0 as possible (where there is less error).
minn and maxn are important to avoid misspelings when typing. So if people search for "pizzza", for example, they will get the same results as "pizza". On the other hand, it significantly increases the final size of the model. I'll explain later how to fix this.
If you run the command, you'll see that the training time is much faster than using Tensorflow, with 20min maximum.
Evaluation
To know how well your model is doing, one of the things to look at during the training, as I said, is how the loss is closer to zero. We can also look how the accuracy is closer to 100. However, once it's already trained we can evaluate how well the model is doing by looking at two other factors: Recall and precision. To do this, FastText has a test command that can be applied to a set of sentences that have not been used during training.
Reducing the model size: Quantization
One problem we encountered was that the size of the model occupied 400mb, so it was totally unfeasible to be used in the browser... This is the cost we include for avoiding misspelings with minn and maxn parameters.
To solve this, we use a well-known technique in machine learning called quantization, which consists of reducing the memory size reserved for each weight.
Fortunately, FastText has its own implementation to apply quantization in its models. For more details they published a paper.
It's important to be aware that applying quantization is not a panacea, and that we are likely to lose some model accuracy.
We apply the quantization with this command:
./fasttext quantize -output model -input data/dataset.txt -qnorm -retrain -epoch 1 -cutoff 100000With this, we drop from 400mb to 4mb! 100 times less. 4mb is still big for the browser, but more feasible...
Using the model on the browser
To use the model trained with FastText from the browser, it is necessary to load it via WebAssembly. However, you don't require a WebAssembly knowledge as you can use the fasttext.js file which has all the glue code.
We can load the model dynamically with the following function:
const [model, setModel] = useState()
async function onLoadModel() {
const { FastText, addOnPostRun } = await import('./fasttext.js')
addOnPostRun(async () => {
const ft = new FastText()
setModel(await ft.loadModel('./model.ftz'))
})
}In the first part of the above example we've loaded the fasttext library. Then we've loaded the model and saved it, in this case, in the React state, so that we can use it later.
For label prediction through a text, we can use this function:
function predictLabelsFromText(text) {
const threshold = 0.5
const predictions = []
const numLabels = 5
const res = model.predict(normalize(text), numLabels, 0)
for (let i = 0; i < res.size(); i += 1) {
predictions.push(res.get(i))
}
return predictions
.filter(([score]) => score > threshold)
.sort(([scoreA], [scoreB]) => scoreB - scoreA)
.map(([score, label]) => label.replace('__label__', ''))
}Given a text, this function returns the 5 related labels (if the probability is higher than 50%, controled by the threshold).
Compared to Tensorflow, the prediction here is very fast.
Conclusions
In this article we have seen how to train a text prediction model easily using FastText and how to use it directly from the browser.
The example used in the article is a real example of a project we developed at Vinissimus, in which, given a text about food, relates to the referenced food labels in order to be able to recommend a wine.
You can test the result in: